Source
# Let's keep our notebook clean, so it's a little more readable!
import warnings
warnings.filterwarnings('ignore')Predict age from resting state fMRI with scikit-learn¶
We will integrate what we’ve learned in the previous sections to extract data from several resting state fMRI images, and use that data as features in a machine learning model.
The dataset consists of children (ages 3-13) and young adults (ages 18-39). We will use resting state fMRI data to try to predict who are adults and who are children.
Load the data¶
# change this to the location where you want the data to get downloaded
data_dir = './nilearn_data'
# Now fetch the data
from nilearn import datasets
development_dataset = datasets.fetch_development_fmri(
data_dir=data_dir,
reduce_confounds = False
)
data = development_dataset.func
confounds = development_dataset.confoundsOutput
How many individual subjects do we have?
len(data)155Get Y (our target) and assess its distribution¶
# Let's load the phenotype data
import pandas as pd
pheno = pd.DataFrame(development_dataset.phenotypic)
pheno.head(4)Looks like there is a column labeling children and adults. Let’s capture it in a variable
y_ageclass = pheno['Child_Adult']
y_ageclass.unique()array(['adult', 'child'], dtype=object)Let’s have a look at the distribution of our target variable
import matplotlib.pyplot as plt
import seaborn as sns
sns.countplot(x=y_ageclass)
pheno.Child_Adult.value_counts()Child_Adult
child 122
adult 33
Name: count, dtype: int64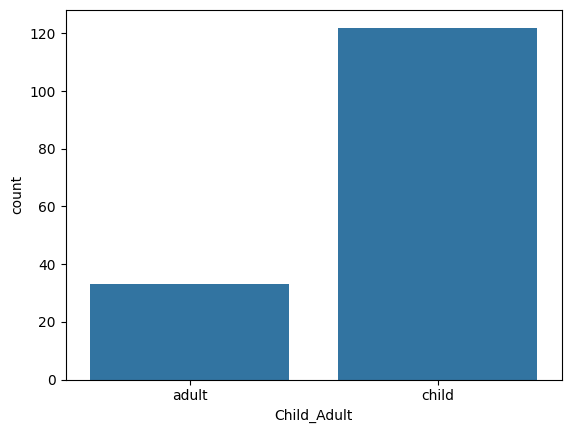
This is very unbalanced -- there seems to be many more children than adults. It is something we can accomodate to a degree when training our model, but it is not within the scope of this tutorial. So let’s select an arbitrary subset of the children to match the number of adults. As the 32 adults are at the beginning of the frame, this is easy to do:
data = data[0:66]
pheno = pheno.head(66)
y_ageclass = pheno['Child_Adult']Extract features with nilearn masker¶
Here, we are going to use the same techniques we learned in the previous tutorial to extract resting state fMRI connectivity features from every subject. Let’s reload our atlas, and re-initiate our masker and correlation_measure.
datasets.fetch_atlas_basc_multiscale_2015?Signature:
datasets.fetch_atlas_basc_multiscale_2015(
data_dir=None,
url=None,
resume=True,
verbose=1,
resolution=7,
version='sym',
)
Docstring:
Download and load multiscale functional brain parcellations.
This :term:`Deterministic atlas` includes group brain parcellations
generated from resting-state
:term:`functional magnetic resonance images<fMRI>` from about 200 young
healthy subjects.
Multiple resolutions (number of networks) are available, among
7, 12, 20, 36, 64, 122, 197, 325, 444. The brain parcellations
have been generated using a method called bootstrap analysis of
stable clusters called as BASC :footcite:t:`Bellec2010`,
and the resolutions have been selected using a data-driven method
called MSTEPS :footcite:t:`Bellec2013`.
Note that two versions of the template are available, 'sym' or 'asym'.
The 'asym' type contains brain images that have been registered in the
asymmetric version of the :term:`MNI` brain template (reflecting that
the brain is asymmetric), while the 'sym' type contains images registered
in the symmetric version of the :term:`MNI` template.
The symmetric template has been forced to be symmetric anatomically, and
is therefore ideally suited to study homotopic functional connections in
:term:`fMRI`: finding homotopic regions simply consists of flipping the
x-axis of the template.
.. nilearn_versionadded:: 0.2.3
Parameters
----------
data_dir : :obj:`pathlib.Path` or :obj:`str` or None, optional
Path where data should be downloaded.
By default, files are downloaded in a ``nilearn_data`` folder
in the home directory of the user.
See also ``nilearn.datasets.utils.get_data_dirs``.
url : :obj:`str` or None, default=None
URL of file to download.
Override download URL.
Used for test only (or if you setup a mirror of the data).
resume : :obj:`bool`, default=True
Whether to resume download of a partly-downloaded file.
verbose : :obj:`bool` or :obj:`int`, default=1
Verbosity level (``0`` or ``False`` means no message).
resolution : :obj:`int`, default=7
Number of networks in the dictionary.
Valid resolutions available are
{7, 12, 20, 36, 64, 122, 197, 325, 444}
.. nilearn_versionchanged: 0.13.0
Default changed to ``7``.
version : {'sym', 'asym'}, default='sym'
Available versions are 'sym' or 'asym'.
By default all scales of brain parcellations of version 'sym'
will be returned.
Returns
-------
data : :class:`sklearn.utils.Bunch`
Dictionary-like object, Keys are:
- maps: :obj:`str`
Path to Nifti file of the brain parcellation.
Images have shape ``(53, 64, 52)`` and contain consecutive integer
values from 0 to the selected number of networks (scale).
- 'description' : :obj:`str`
Description of the dataset.
- lut : :obj:`pandas.DataFrame`
Act as a look up table (lut)
with at least columns 'index' and 'name'.
Formatted according to 'dseg.tsv' format from
`BIDS <https://bids-specification.readthedocs.io/en/latest/derivatives/imaging.html#common-image-derived-labels>`_.
- 'template' : :obj:`str`
The standardized space of analysis
in which the atlas results are provided.
When known it should be a valid template name
taken from the spaces described in
`the BIDS specification <https://bids-specification.readthedocs.io/en/latest/appendices/coordinate-systems.html#image-based-coordinate-systems>`_.
- 'atlas_type' : :obj:`str`
Type of atlas.
See :term:`Probabilistic atlas` and :term:`Deterministic atlas`.
References
----------
.. footbibliography::
Notes
-----
If the dataset files are already present in the user's Nilearn data
directory, this fetcher will **not** re-download them. To force a fresh
download, you can remove the existing dataset folder from your local
Nilearn data directory.
For more details on :ref:`how Nilearn stores datasets <datasets>`.
For more information on this dataset's structure, see
https://figshare.com/articles/dataset/Group_multiscale_functional_template_generated_with_BASC_on_the_Cambridge_sample/1285615
File: ~/.local/lib/python3.10/site-packages/nilearn/datasets/atlas.py
Type: functionfrom nilearn.maskers import NiftiLabelsMasker
from nilearn.connectome import ConnectivityMeasure
# load atlas
basc = datasets.fetch_atlas_basc_multiscale_2015(data_dir=data_dir, resolution=64)
atlas_filename = basc.maps
# initialize masker (change verbosity)
masker = NiftiLabelsMasker(labels_img=atlas_filename, standardize='zscore_sample',
memory='nilearn_cache', resampling_target="data",
detrend=True, verbose=0)
# initialize correlation measure, set to vectorize
correlation_measure = ConnectivityMeasure(kind='correlation', vectorize=True,
discard_diagonal=True)Output
Okay -- now that we have that taken care of, let’s load all of the data!
NOTE: On a laptop, this might take a few minutes.
all_features = [] # here is where we will put the data (a container)
for i,sub in enumerate(data):
# extract the timeseries from the ROIs in the atlas
time_series = masker.fit_transform(sub, confounds=confounds[i])
# create a region x region correlation matrix
correlation_matrix = correlation_measure.fit_transform([time_series])[0]
# add to our container
all_features.append(correlation_matrix)
# keep track of status
print('finished %s of %s'%(i+1,len(data)))Output
finished 1 of 66
finished 2 of 66
finished 3 of 66
finished 4 of 66
finished 5 of 66
finished 6 of 66
finished 7 of 66
finished 8 of 66
finished 9 of 66
finished 10 of 66
finished 11 of 66
finished 12 of 66
finished 13 of 66
finished 14 of 66
finished 15 of 66
finished 16 of 66
finished 17 of 66
finished 18 of 66
finished 19 of 66
finished 20 of 66
finished 21 of 66
finished 22 of 66
finished 23 of 66
finished 24 of 66
finished 25 of 66
finished 26 of 66
finished 27 of 66
finished 28 of 66
finished 29 of 66
finished 30 of 66
finished 31 of 66
finished 32 of 66
finished 33 of 66
finished 34 of 66
finished 35 of 66
finished 36 of 66
finished 37 of 66
finished 38 of 66
finished 39 of 66
finished 40 of 66
finished 41 of 66
finished 42 of 66
finished 43 of 66
finished 44 of 66
finished 45 of 66
finished 46 of 66
finished 47 of 66
finished 48 of 66
finished 49 of 66
finished 50 of 66
finished 51 of 66
finished 52 of 66
finished 53 of 66
finished 54 of 66
finished 55 of 66
finished 56 of 66
finished 57 of 66
finished 58 of 66
finished 59 of 66
finished 60 of 66
finished 61 of 66
finished 62 of 66
finished 63 of 66
finished 64 of 66
finished 65 of 66
finished 66 of 66
finished 2 of 66
finished 3 of 66
finished 4 of 66
finished 5 of 66
finished 6 of 66
finished 7 of 66
finished 8 of 66
finished 9 of 66
finished 10 of 66
finished 11 of 66
finished 12 of 66
finished 13 of 66
finished 14 of 66
finished 15 of 66
finished 16 of 66
finished 17 of 66
finished 18 of 66
finished 19 of 66
finished 20 of 66
finished 21 of 66
finished 22 of 66
finished 23 of 66
finished 24 of 66
finished 25 of 66
finished 26 of 66
finished 27 of 66
finished 28 of 66
finished 29 of 66
finished 30 of 66
finished 31 of 66
finished 32 of 66
finished 33 of 66
finished 34 of 66
finished 35 of 66
finished 36 of 66
finished 37 of 66
finished 38 of 66
finished 39 of 66
finished 40 of 66
finished 41 of 66
finished 42 of 66
finished 43 of 66
finished 44 of 66
finished 45 of 66
finished 46 of 66
finished 47 of 66
finished 48 of 66
finished 49 of 66
finished 50 of 66
finished 51 of 66
finished 52 of 66
finished 53 of 66
finished 54 of 66
finished 55 of 66
finished 56 of 66
finished 57 of 66
finished 58 of 66
finished 59 of 66
finished 60 of 66
finished 61 of 66
finished 62 of 66
finished 63 of 66
finished 64 of 66
finished 65 of 66
finished 66 of 66
# Let's save the data to disk
import numpy as np
name_connectome = 'connectomes_developmental_dataset'
np.savez_compressed(f'./{name_connectome}', a=all_features)In case you do not want to run the full loop on your computer, you can load the output of the loop here!
feat_file = f'{name_connectome}.npz'
X_features = np.load(feat_file)['a']X_features.shape(66, 2016)Okay so we’ve got our features.
We can visualize our feature matrix
import matplotlib.pyplot as plt
plt.imshow(X_features, aspect='auto', interpolation='nearest')
plt.colorbar()
plt.title('feature matrix')
plt.xlabel('features')
plt.ylabel('subjects')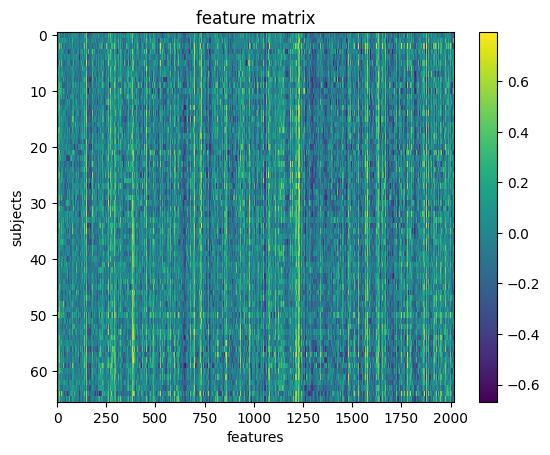
Prepare data for machine learning¶
Here, we will define a training sample where we can play around with our models. We will also set aside a test sample that we will not touch until the end.
We want to be sure that our training and test sample are matched! We can do that with a stratified split. Specifically, we will stratify by age class.
y_ageclass.shape(66,)from sklearn.model_selection import train_test_split
# Split the sample to training/test and
# stratify by age class, and also shuffle the data.
X_train, X_test, y_train, y_test = train_test_split(X_features, # x
y_ageclass, # y
test_size = 0.2, # 80%/20% split
shuffle = True, # shuffle dataset
# before splitting
stratify = y_ageclass, # keep
# distribution
# of ageclass
# consistent
# betw. train
# & test sets.
random_state = 123 # same shuffle each
# time
)
# print the size of our training and test groups
print('training:', len(X_train),
'testing:', len(X_test))training: 52 testing: 14
Let’s visualize the distributions to be sure they are matched
fig,(ax1,ax2) = plt.subplots(2)
sns.countplot(x=y_train, ax=ax1, order=['child','adult'])
ax1.set_title('Train')
sns.countplot(x=y_test, ax=ax2, order=['child','adult'])
ax2.set_title('Test')
plt.tight_layout()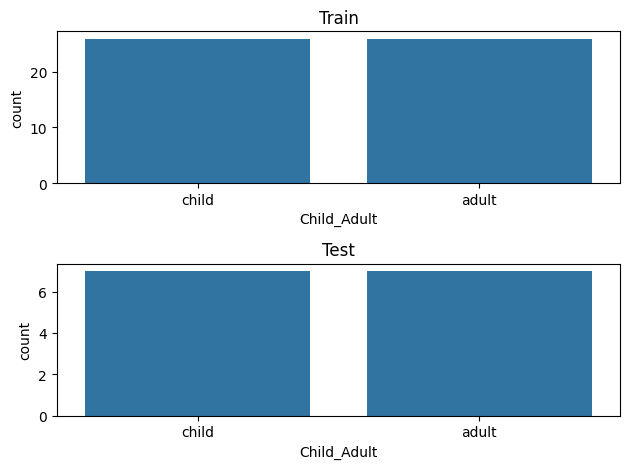
Run your first model!¶
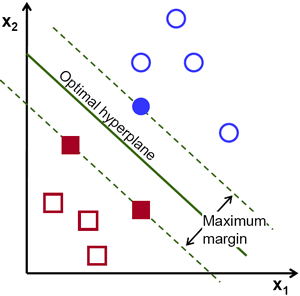
Machine learning can get pretty fancy very quickly. We’ll start with a very standard classification model called a Support Vector Classifier (SVC).
While this may seem unambitious, simple models can be very robust. And we don’t have enough data to create more complex models.
For more information, see this excellent resource:
https://
First, a quick review of SVM!
Let’s fit our first model!
from sklearn.svm import SVC
l_svc = SVC(kernel='linear', class_weight='balanced') # define the model
l_svc.fit(X_train, y_train) # fit the modelWell... that was easy. Let’s see how well the model learned the data!
We can judge our model on several criteria:
Accuracy: The proportion of predictions that were correct overall
Precision: Accuracy of cases predicted as positive
Recall: Number of true positives correctly predicted to be positive
f1 score: A balance between precision and recall
Or, for a more visual explanation...

Let’s train a model¶
from sklearn.metrics import classification_report, confusion_matrix, precision_score, f1_score
# predict the training data based on the model
y_pred = l_svc.predict(X_train)
# calculate the model accuracy
acc = l_svc.score(X_train, y_train)
# calculate the model precision, recall and f1, all in one convenient report!
cr = classification_report(y_true=y_train,
y_pred = y_pred)
# get a table to help us break down these scores
cm = confusion_matrix(y_true=y_train, y_pred = y_pred)Let’s view our results and plot them all at once!
import itertools
from pandas import DataFrame
# print results
print('accuracy:', acc)
print(cr)
# plot confusion matrix
cmdf = DataFrame(cm, index = ['Adult','Child'], columns = ['Adult','Child'])
sns.heatmap(cmdf, cmap = 'RdBu_r')
plt.xlabel('Predicted')
plt.ylabel('Observed')
# label cells in matrix
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j+0.5, i+0.5, format(cm[i, j], 'd'),
horizontalalignment="center",
color="white")accuracy: 1.0
precision recall f1-score support
adult 1.00 1.00 1.00 26
child 1.00 1.00 1.00 26
accuracy 1.00 52
macro avg 1.00 1.00 1.00 52
weighted avg 1.00 1.00 1.00 52
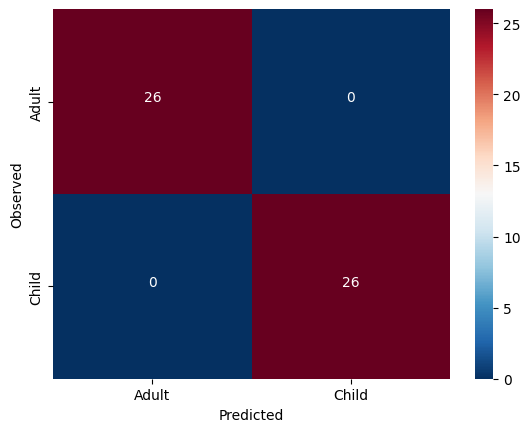
Solution
The model was not cross validated.
Scroll down and unfold the cells to see the answer!
Fit the model with the training data and cross-validation¶
Source
from sklearn.model_selection import cross_val_predict, cross_val_score
# predict
y_pred = cross_val_predict(l_svc, X_train, y_train,
groups=y_train, cv=3)
# scores
acc = cross_val_score(l_svc, X_train, y_train,
groups=y_train, cv=3)Output
We can look at the accuracy of the predictions for each fold of the cross-validation
Source
for i in range(len(acc)):
print('Fold %s -- Acc = %s'%(i, acc[i]))Output
Fold 0 -- Acc = 0.8888888888888888
Fold 1 -- Acc = 1.0
Fold 2 -- Acc = 0.8823529411764706
We can also look at the overall accuracy of the model
Source
from sklearn.metrics import accuracy_score
overall_acc = accuracy_score(y_pred = y_pred, y_true = y_train)
overall_cr = classification_report(y_pred = y_pred, y_true = y_train)
overall_cm = confusion_matrix(y_pred = y_pred, y_true = y_train)
print('Accuracy:',overall_acc)
print(overall_cr)Output
Accuracy: 0.9230769230769231
precision recall f1-score support
adult 0.96 0.88 0.92 26
child 0.89 0.96 0.93 26
accuracy 0.92 52
macro avg 0.93 0.92 0.92 52
weighted avg 0.93 0.92 0.92 52
Source
thresh = overall_cm.max() / 2
cmdf = DataFrame(overall_cm, index = ['Adult','Child'], columns = ['Adult','Child'])
sns.heatmap(cmdf, cmap='copper')
plt.xlabel('Predicted')
plt.ylabel('Observed')
for i, j in itertools.product(range(overall_cm.shape[0]), range(overall_cm.shape[1])):
plt.text(j+0.5, i+0.5, format(overall_cm[i, j], 'd'),
horizontalalignment="center",
color="white")Output
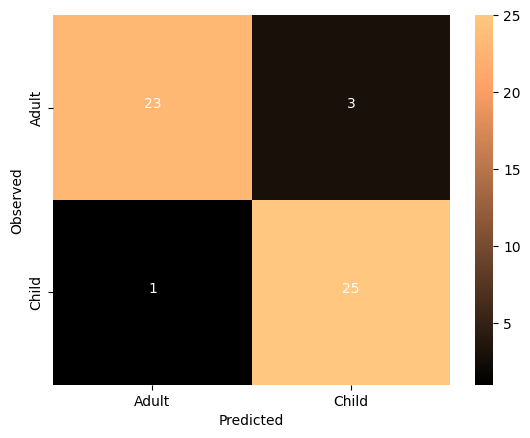
The imporved model seems to be performing very well. Let’s run some null model:
Source
from sklearn.model_selection import permutation_test_score
score, permutation_score, pvalue = permutation_test_score(
l_svc, X_train, y_train, cv=3, scoring="accuracy",
n_jobs=2, n_permutations=100)
print(f'accuracy {score}, average permutation accuracy {permutation_score.mean()}, p value {pvalue}')Output
accuracy 0.9237472766884531, average permutation accuracy 0.4946732026143792, p value 0.009900990099009901
so, as the classes are balanced, the chance level is close to 50%. The model performs significantly higher than chance.
Tweak your model¶
It’s very important to learn when and where it’s appropriate to “tweak” your model.
Since we have done all of the previous analysis with our training data, it’s fine to try different models. But we absolutely cannot “test” it on our left-out-data. If we do, we are in great danger of overfitting.
We could try other models, or tweak hyperparameters, but we are probably not powered sufficiently to do so, and would once again risk overfitting.
But as a demonstration, we could see the impact of “scaling” our data. Certain machine learning algorithms perform better when all the input data is transformed to a uniform range of values. This is often between 0 and 1, or mean centered around with unit variance. We can perhaps look at the performance of the model after scaling the data.
# Scale the training data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().fit(X_train)
X_train_scl = scaler.transform(X_train)plt.imshow(X_train, aspect='auto', interpolation='nearest')
plt.colorbar()
plt.title('Training Data')
plt.xlabel('features')
plt.ylabel('subjects')
plt.imshow(X_train_scl, aspect='auto', interpolation='nearest')
plt.colorbar()
plt.title('Scaled Training Data')
plt.xlabel('features')
plt.ylabel('subjects')
# repeat the steps above to re-fit the model
# and assess its performance
# don't forget to switch X_train to X_train_scl
# predict
y_pred = cross_val_predict(l_svc, X_train_scl, y_train,
groups=y_train, cv=3)
# get scores
overall_acc = accuracy_score(y_pred = y_pred, y_true = y_train)
overall_cr = classification_report(y_pred = y_pred, y_true = y_train)
overall_cm = confusion_matrix(y_pred = y_pred, y_true = y_train)
print('Accuracy:',overall_acc)
print(overall_cr)
# plot
thresh = overall_cm.max() / 2
cmdf = DataFrame(overall_cm, index = ['Adult','Child'], columns = ['Adult','Child'])
sns.heatmap(cmdf, cmap='copper')
plt.xlabel('Predicted')
plt.ylabel('Observed')
for i, j in itertools.product(range(overall_cm.shape[0]), range(overall_cm.shape[1])):
plt.text(j+0.5, i+0.5, format(overall_cm[i, j], 'd'),
horizontalalignment="center",
color="white")Accuracy: 0.8846153846153846
precision recall f1-score support
adult 0.95 0.81 0.88 26
child 0.83 0.96 0.89 26
accuracy 0.88 52
macro avg 0.89 0.88 0.88 52
weighted avg 0.89 0.88 0.88 52
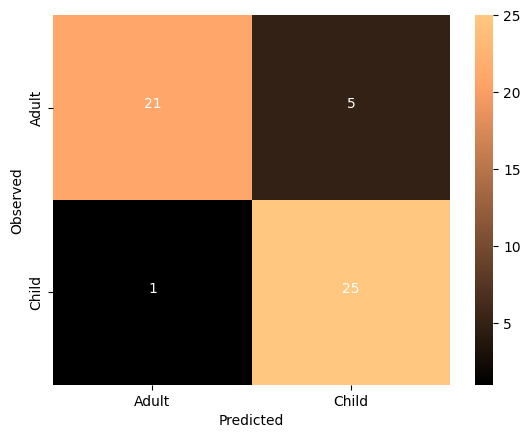
What do you think about the results of this model compared to the non-transformed model?
Answer
The SVC model has a parameter kernel and there are multiple options.
You can check the documentation to find out more!
#l_svc = SVC(kernel='linear') # define the modelCan our model classify children from adults in completely un-seen data?¶
Now that we’ve fit a model that we think has possibly learned how to decode childhood vs adulthood based on resting state fMRI signal, let’s put it to the test. We will train our model on all the training data, and try to predict the age of the subjects we left out at the beginning of this section.
Because we performed a transformation on our training data, we will need to transform our testing data using the same information!
# Notice how we use the Scaler that was fit to X_train and apply it to X_test,
# rather than creating a new Scaler for X_test
X_test_scl = scaler.transform(X_test)And now for the moment of truth!¶
No cross-validation needed here. We simply fit the model with the training data and use it to predict the testing data
I’m so nervous. Let’s just do it all in one cell
l_svc.fit(X_train_scl, y_train) # fit to training data
y_pred = l_svc.predict(X_test_scl) # classify age class using testing data
acc = l_svc.score(X_test_scl, y_test) # get accuracy
cr = classification_report(y_pred=y_pred, y_true=y_test) # get prec., recall & f1
cm = confusion_matrix(y_pred=y_pred, y_true=y_test) # get confusion matrix
# print results
print('accuracy =', acc)
print(cr)
# plot results
thresh = cm.max() / 2
cmdf = DataFrame(cm, index = ['Adult','Child'], columns = ['Adult','Child'])
sns.heatmap(cmdf, cmap='RdBu_r')
plt.xlabel('Predicted')
plt.ylabel('Observed')
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j+0.5, i+0.5, format(cm[i, j], 'd'),
horizontalalignment="center",
color="white")accuracy = 0.9285714285714286
precision recall f1-score support
adult 1.00 0.86 0.92 7
child 0.88 1.00 0.93 7
accuracy 0.93 14
macro avg 0.94 0.93 0.93 14
weighted avg 0.94 0.93 0.93 14
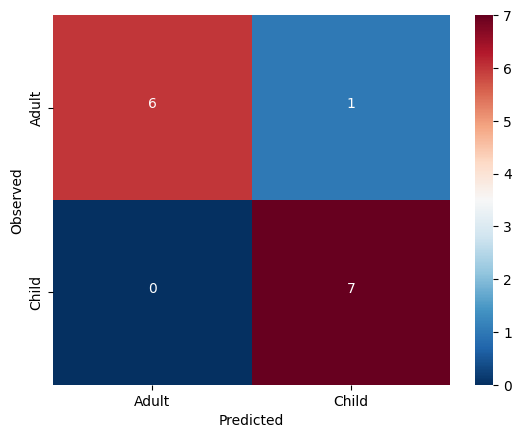
The model generalized very well! We may have found something in this data which does seem to be systematically related to age ... but what?
Interpreting model feature importances¶
Interpreting the feature importances of a machine learning model is a real can of worms. This is an area of active research. Unfortunately, it’s hard to trust the feature importance of some models.
You can find a whole tutorial on this subject here:
http://
For now, we’ll just eschew better judgement and take a look at our feature importances.
We can access the feature importances (weights) used by the model
l_svc.coef_array([[ 0.00336509, 0.00455223, -0.00039927, ..., -0.00286534,
-0.00259382, -0.00027196]])Let’s plot these weights to see their distribution better
plt.bar(range(l_svc.coef_.shape[-1]),l_svc.coef_[0])
plt.title('feature importances')
plt.xlabel('feature')
plt.ylabel('weight')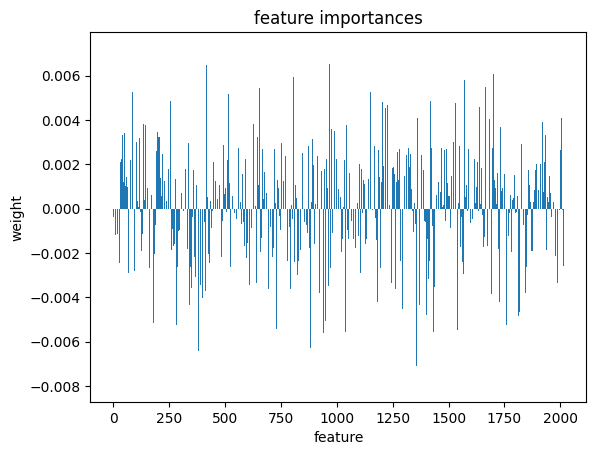
Or perhaps it will be easier to visualize this information as a matrix similar to the one we started with
We can use the correlation measure from before to perform an inverse transform
correlation_measure.inverse_transform(l_svc.coef_).shape(1, 64, 64)from nilearn import plotting
feat_exp_matrix = correlation_measure.inverse_transform(l_svc.coef_)[0]
plotting.plot_matrix(feat_exp_matrix, figure=(10, 8),
labels=range(feat_exp_matrix.shape[0]),
reorder=False,
tri='lower')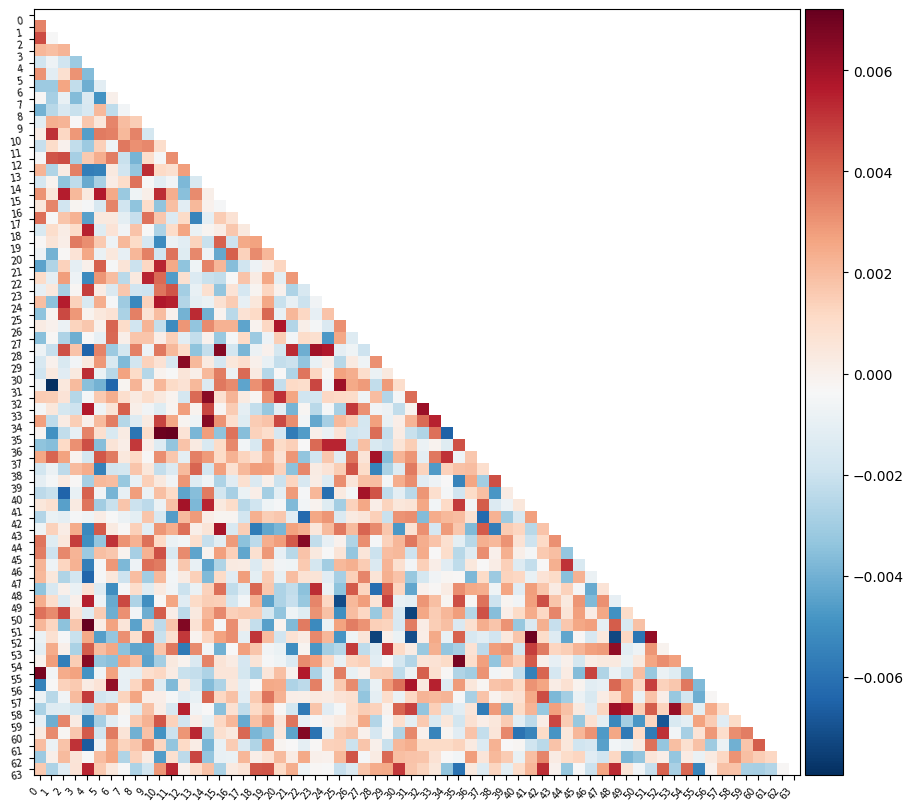
Let’s see if we can throw those features onto an actual brain.
First, we’ll need to gather the coordinates of each ROI of our atlas
coords = plotting.find_parcellation_cut_coords(atlas_filename)And now we can use our feature matrix and the wonders of nilearn to create a connectome map where each node is an ROI, and each connection is weighted by the importance of the feature to the model
plotting.plot_connectome(feat_exp_matrix, coords, colorbar=True)<nilearn.plotting.displays._projectors.OrthoProjector at 0x7ea1c9512a40>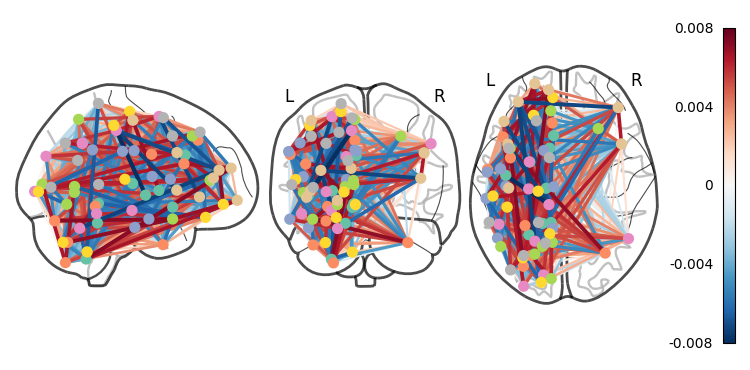
Whoa!! That’s...a lot to process. Maybe let’s threshold the edges so that only the most important connections are visualized
plotting.plot_connectome(feat_exp_matrix, coords, colorbar=True, edge_threshold=0.005)<nilearn.plotting.displays._projectors.OrthoProjector at 0x7ea1be7678e0>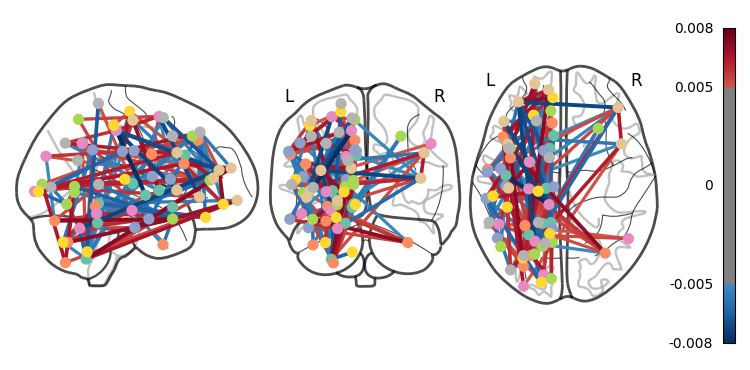
That’s definitely an improvement, but it’s still a bit hard to see what’s going on. Nilearn has a new feature that lets us view this data interactively!
plotting.view_connectome(feat_exp_matrix, coords, edge_threshold='90%')You can choose to open the figure in a browser with the following lines:
# view = plotting.view_connectome(feat_exp_matrix, coords, edge_threshold='90%')
# view.open_in_browser()Exercises¶
We walked through a lot of mistakes in this tutorial, try to start a fresh notebook and create a clean, and correct version of the workflow.
The dataset contains the exact age of the subjects. Try to predict the age of the subjects instead of the age class. Hint - use regression instead of classification.
Try other atlases - does a different atlas change the results?
Advanced - try to implement different atlases as part of the parameter tuning.